
こんにちは、にいるです。
最近、Data Architecture and Management デザイナーの勉強をはじめました。
試験もそうですが、それよりもエンジニアとしてのデータベース設計について学びたいなと思い、ドキュメントやガイドを読んだことをまとめておこうと思います。
1.データスキューについて
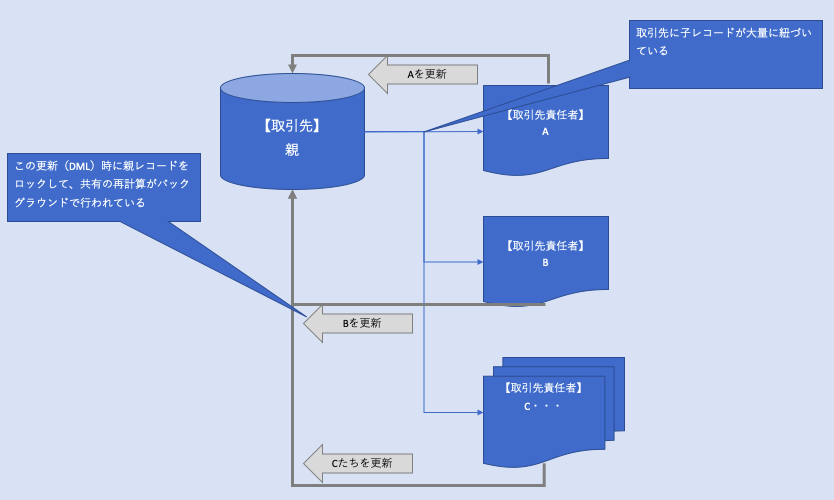
データスキューとは、取引先レコードに大量の子レコードが紐づいている状態です。
例えば取引先が不明な場合は、とりあえずという意味で「保留」という取引先を作成しこの親に紐付けておくことがあると思います。
運用ユーザから見れば問題ないように見えますが、システム的に見るとこの管理方法は危ないです。
というのも、「保留」を親に持っている取引先責任者レコードAを更新した場合、その親である取引先のレコードに対して、レコードロックと共有再計算の処理が走るからです。
なので、「保留」という親を持つ取引先責任者のレコードを条件に更新をする場合、各取引先責任者レコードの更新に対して、毎回取引先レコードにロックをかけます。
まずこの時点で、取引先責任者レコードAと取引先責任者レコードBの処理で親レコードに対するロックの競合が起き、更新処理が完了しない可能性が発生します。
よくある「UNABLE_TO_LOCK_ROW」エラーですね。
共有についても同じく、親に対する共有ルールが存在する場合に、レコードが更新されるので一回一回のレコード更新時にロール階層の共有と共有ルールの再計算が走ります。
10件などの処理数であれば問題はないかもしれませんが、大量データに対する処理の場合はとても注意が必要になってきます。
Salesforceとしては親に10,000件の子レコードが紐づくのをよしとしていないので、10,000件を目安に調整した方がいいです。
保留(北海道)、保留(教育)などエリアや種類などの属性で区別して、分散できるように運用設計しておくことが大事ですね。
どうしても難しい場合は、組織の共有設定で[公開/参照・更新可能]でアクセス権限を緩和しておきましょう。
2.所有権スキュー
同様に所有権スキューというものもあります。
これは1人のユーザが大量のレコードの所有者になっている状況です。
これを回避するためには、事前にレコード所有者の設計を定義しておく必要があります。
ただ、どうしても1人のユーザに大量のレコードの所有者として割り当てる場合は、そのブランチのロール階層で最上位に設定して共有ルールのみで割り当てられるようにしておきます。
こうしておけば、ロール階層が変更されたとしても大量レコードの所有者は最上位にいるので、再計算の対象外となります。
この設定をする場合、このユーザを他のロールに変更するのはNGなので注意しましょう。
3.参照スキュー
もう一点、参照スキューというスキューもあります。
Salesforceはどのオブジェクトにも参照関係を作成することができます。
オブジェクトが増えるに連れて、関連性を持たせてデータを管理していくと思いますが、これを繰り返していくと次のような状況になっていることがあります。
- 複雑なリレーションになっていて個々のリレーションがよくわからない
- このオブジェクトがどうなってAccountと紐づいているかわからない
- 全体がよく見えない
参照スキューはこのような状況で発生します。
参照しすぎて保存実行時にいろいろなレコードをロックしにかかり、共有の再計算が起こってしまいます。
なので、取引先スキューと同じくできるだけ子レコードはあまり多く持たないように退避できるデータは退避しておきましょう。
4.まとめ
いかがでしたでしょうか。
読んで理解して思ったことは、Salesforceプラットフォームにすごく助けられているなと思いました。
無茶な実装や負荷の高い処理を平気で実装してもSalesforceのシステムがマンパワーで補ってくれてるので、エンジニアは少しでも負荷が低く、処理的に効率の良い方法で実装しないと行けないなと。
頭でわかっていても、方法を知らなければ意味がないのでそこを埋めていけるように頑張ります。
皆さんも興味があればアーキテクチャ関連の記事を読んでみてはどうですか?
他にも色々と標準機能やSalesforce機能について紹介していますので、ご覧ください。
ではでは!




コメント