

こんにちは、にいるです。
今回はBig Objectについて、見ていきたいと思います。
前々から[設定]メニューにあることは知っていましたが、Big Objectがどんな用途で使用するものか全く知らなく、、、
SalesCloudの試験範囲でもあるので、全体像から見ていきます。
・【Trailhead】Big Objectの使用開始
・【ヘルプ】Big Objects
・【ヘルプ】Async Query Input
1.Big Objectとは
Big Objectとは、Salesforce上で10億件以上のデータを保存、管理することができる機能です。
1-1.Big Objectの種類
Big Objectは2つの分類に分けられます。
1つは標準Big Objectでもう1つはカスタムBig Objectです。
標準Big ObjectはSalesforceにデフォルトで定義されているオブジェクトです。
カスタムBig Objectはユーザが独自に定義できるオブジェクトです。
1-2.Big Objectの使用目的
Big Objectの主な使用目的は3つあります。
| 使用目的 | 説明 |
| 顧客の360度ビュー | 全顧客の全データの参照 |
| 監査と追跡 | ユーザのSalesforce利用状況の追跡 |
| 履歴アーカイブ | データの履歴管理 |
あらゆるデータを保存しておくイメージが強いと思います。
2.カスタムBig Objectの設定方法
実際にカスタムBig Objectを作成したいと思います。
やることは3つで、Big Object→カスタム項目→インデックスを作成します。
まずは、[設定]メニューの[Big Object]から新規作成ボタンをクリックし、オブジェクト名とAPI名を入力します。
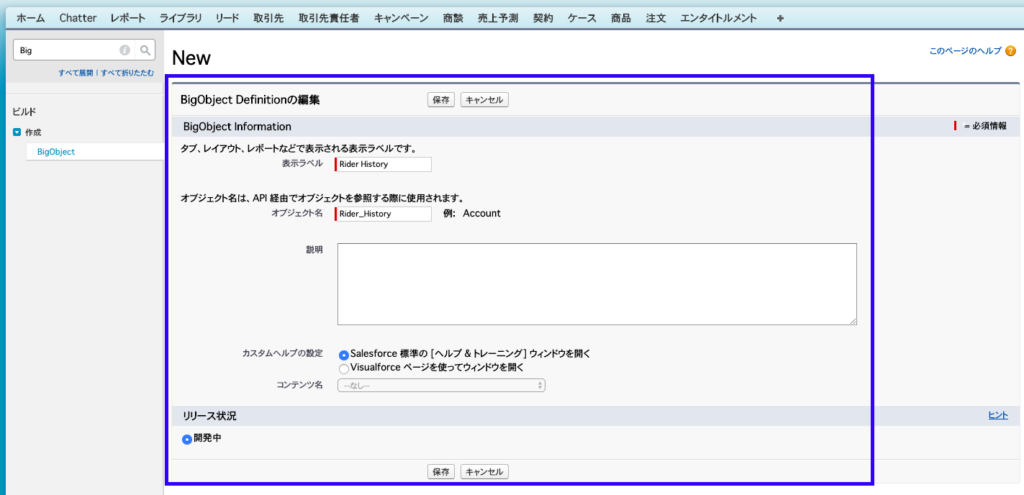

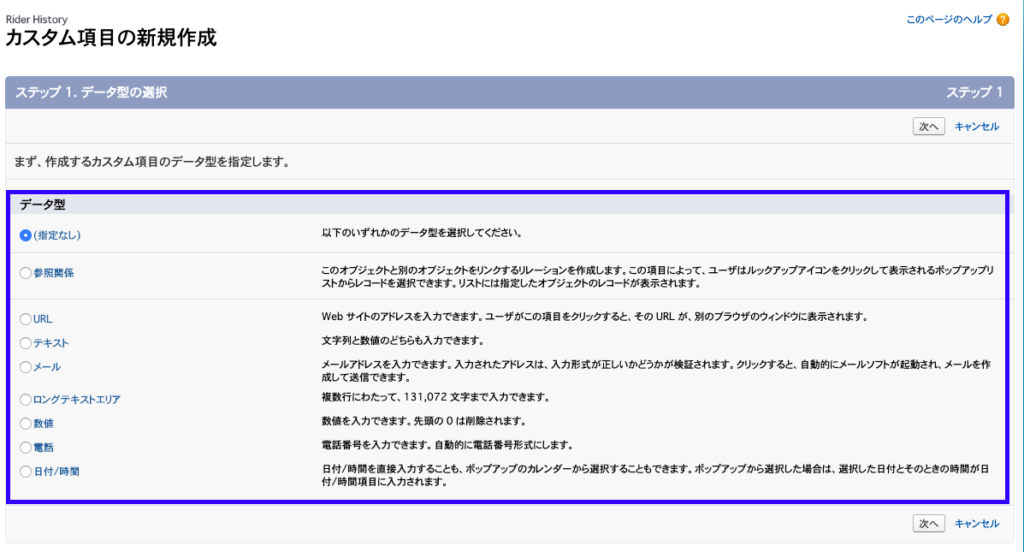
次にカスタム項目を作成していきます。
選べるデータ型はカスタムオブジェクトや標準オブジェクトと違い、選択リストや主従関係のリレーション項目、数式は選べないようです。

作成したBig Objectのサフィックスは「__b」になっていて、項目は「__c」になっていますね。
クエリ使用時には注意しましょう。
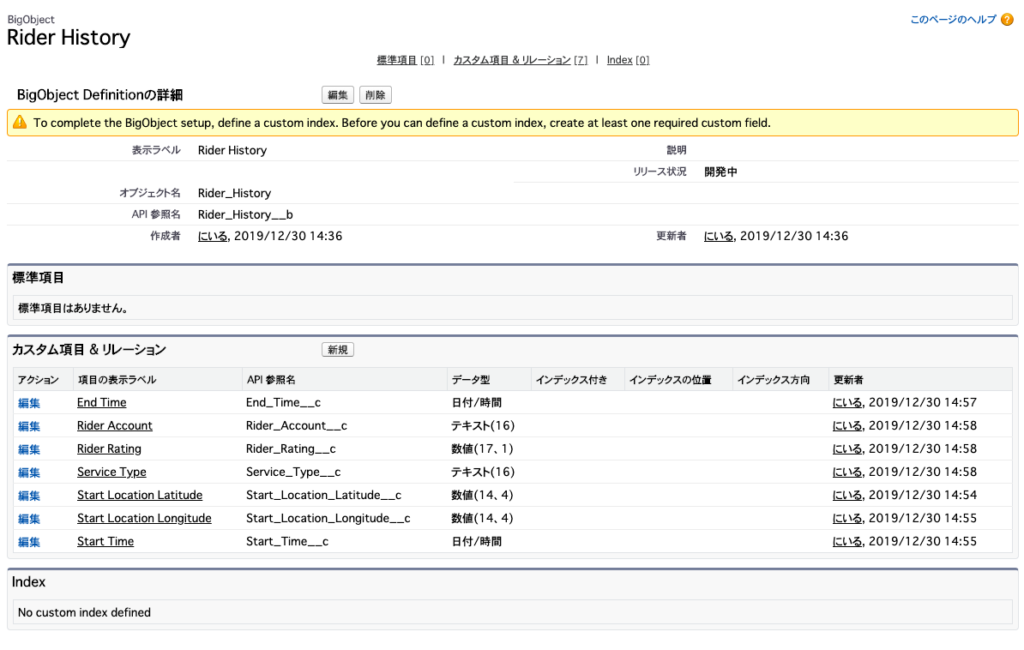

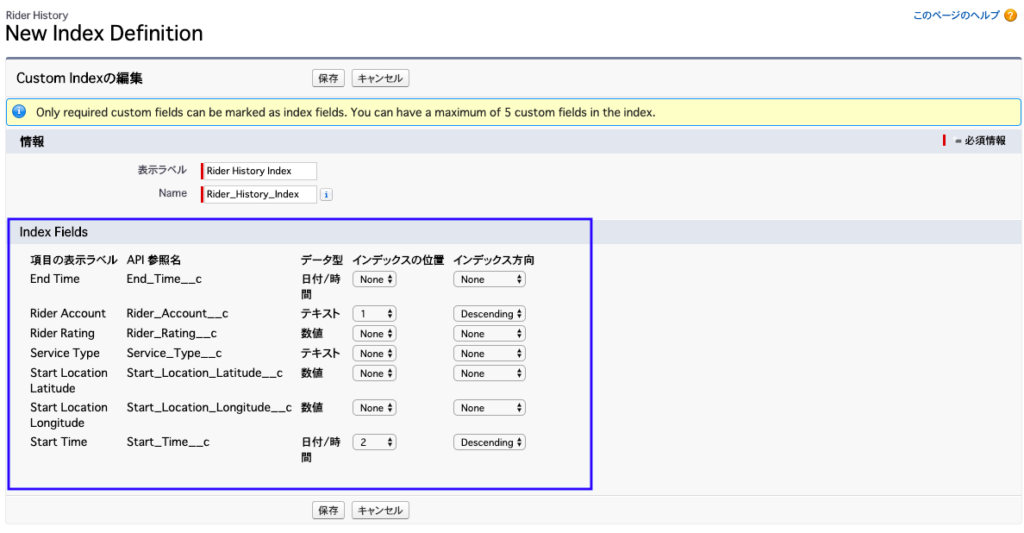
最後にインデックスを作成します。
インデックスを作成する理由は、クエリで操作する項目が決まるからです。
インデックスに使用する項目は入力必須にする必要があるので、予め設計方針は決めておきましょう。
また優先順位も「インデックスの位置」という項目で設定できます。
一番クエリで使用する項目は1にしておきましょう。

項目とインデックスを定義したあとは、Big Objectをリリースするだけです。

Big Objectの作成時は、開発中しか選べなかったですが、カスタム項目とインデックスを定義したので、「リリース済み」も選べるようになっています。
これでSalesforceの組織でBig Objectが使用可能になりました。
3.Big Objectのクエリ
Big ObjectへのアクセスにはSOQLクエリを使用しますが、クエリも2種類あります。
1つは通常のSOQLで、もう1つは非同期SOQLです。
ただ、非同期SOQLは追加のBig Object容量のライセンスでしか使用できません。
標準のSOQLは、返りの結果が少ない件数である時や、UIに表示する必要はある時です。
非同期SOQLは、クエリ対象が何百万ものレコードであるときや、クエリを完了させる必要がある時です。
3-1.標準のSOQL
標準のSOQLの場合、構文は通常通り、SELECT,FROM,WHERE句で構成されます。
ただ、インデックスに追加した項目は必ず、順番通りに使用する必要があります。
例えば,A,B,C項目を順に1からインデックスした場合、下記のようにSELECT句とWHERE句の順番をインデックス通りに揃えないといけません。
|
1 |
SELECT A,B,C FROM BigObject__b WHERE A = "" AND B = "" AND C = "" |
また、ここで使用できる比較演算子も縛りがあります。
クエリの最後の項目だけ「=、、=、IN」の比較演算子を使用でき、それより前の項目では「=」のみしか使用できません。
それに加えて、「!=、LIKE、NOT IN、EXCLUDES、INCLUDES」 演算子は、Big Objectでは使用できません。
標準と言っても、ちょっとした制限がありますね。
3-2.非同期SOQL
非同期SOQLの場合は、2つの使用方法があります。
1つは、Big Objectのデータをカスタムオブジェクトに抽出して、それをレポート、ダッシュボードなどで加工する方法です。
例えば、全てのセッション情報を無造作に取得してBig Objectに登録している場合に使用できます。
下記の場合、
targetObjectがクエリ結果を挿入するオブジェクトで、
targetFieldMapが項目間のマッピングを指定しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ "query": "SELECT End_Location_Lat__c, End_Location_Lon__c, End_Time__c, Start_Location_Lat__c, Start_Location_Lon__c, Start_Time__c, Car_Type__c, Rider__r.FirstName, Rider__r.LastName, Rider__r.Email FROM Rider_Record__b WHERE Star_Rating__c = '5'", "targetObject": "Rider_Reduced__b", "targetFieldMap": {"End_Location_Lat__c":"End_Lat__c", "End_Location_Lon__c":"End_Long__c", "Start_Location_Lat__c": "Start_Lat__c", "Start_Location_Lon__c": "Start_Long__c", "End_Time__c": "End_Time__c", "Start_Time__c": "Start_Time__c", "Car_Type__c": "Car_Type__c", "Rider__r.FirstName": "First_Name__c", "Rider__r.LastName": "Last_Name__c", "Rider__r.Email": "Rider_Email__c" } } |
もう1つは、集計関数を使用した抽出方法です。
使用できる集計関数にはSUM、MIN、MAX、AVG、COUNT、COUNT_DISTINCTです。
これらの集計関数を使用すると、Big Objectからどのデータを抽出するかをより詳細に制御できます。
|
1 2 3 4 |
{"query":"SELECT COUNT(fieldname__c) c, EventTime t FROM LoginEvent group by EventTime", "targetObject":"QueryEvents__c", "targetFieldMap":{"c":"Count__c", "t" : "EventTime__c"} } |
集計した結果をカスタムオブジェクトに登録して、レポートで見れば経時的な変化を出せそうですね。
4.まとめ
いかがでしたでしょうか。
Big Objectは大量のレコードを保存できるので、大量のレコードが必要になるという機会を考えるところから始めないといけません。
ですが、実務上膨大なデータが存在していて、それを垂れ流しにしている場合、もしかしたら貴重な分析に使えるデータがあるかもしれません。
例えば、POSの販売データや連続的なデータレコードの発生など、何かの切り口に使えるかもしれませんね。
皆さんもぜひ使用してみてください。
他にも色々と標準機能やSalesforce機能について紹介しています。
そのまとめ一覧ページはこちらになりますので、よければ見てみてください。
ではでは!

